Log-structured storage engines are a type of database engine that store data in an append-only log file. One of the key challenges in implementing a log-structured storage engine is efficiently looking up data based on a key. To solve this problem, log-structured storage engines often use hash indexes, which map keys to byte offsets in the data file.
Hash Indexes
Hash indexes are a type of data structure used to efficiently look up data based on a key. In a hash index, each key is hashed using a hash function, which produces a numeric value. This numeric value is then used as an index into an array, which contains pointers to the data associated with that key. When a query is made for a particular key, the hash function is applied to the key to produce the corresponding index into the array. The pointer at that index is then followed to retrieve the data associated with the key.
Hash indexes are very fast for lookups, because they only require a single memory access to retrieve the pointer to the data associated with a key. However, they can be inefficient for range queries, because the keys are not stored in sorted order.
Using Hash Indexes in Log-Structured Storage Engines
In a log-structured storage engine, data is stored in an append-only log file. Each write to the database appends a new record to the log file, which contains the data to be written as well as a timestamp and other metadata. To look up data based on a key, the log file is scanned from the beginning to the end, and each record is examined to see if it contains the desired key. This can be slow for large databases, because it requires reading and parsing a large amount of data.
To speed up lookups, log-structured storage engines often use hash indexes. In a log-structured storage engine, each key is mapped to a byte offset in the data file. The hash function used to compute the index is designed to evenly distribute the keys across the array of pointers, so that each bucket in the array contains roughly the same number of keys. This helps ensure that the array can fit in memory, and that lookups are fast.
When a query is made for a particular key, the hash function is applied to the key to compute the corresponding index into the array of pointers. The pointer at that index is then followed to retrieve the byte offset in the data file associated with the key. The data can then be read directly from the data file at the specified offset, without needing to scan the entire log file.
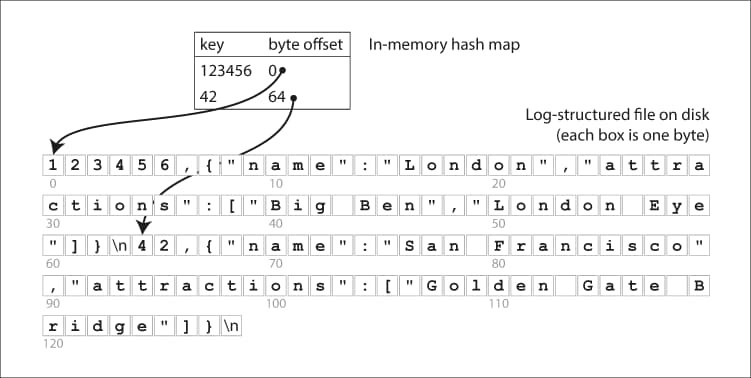
Implementation of the Hash Index
The hash index implementation is straightforward. It uses a Rust HashMap to store the mapping between keys and byte offsets in the data file. Here is the code:
use std::collections::HashMap;
type Index = HashMap<String, usize>;
struct Database {
data: Vec<u8>,
cache: Index,
}
impl Database {
pub fn new() -> Database {
Database {
data: Vec::new(),
cache: HashMap::new(),
}
}
pub fn set(&mut self, key: &str, value: &str) {
self.cache.insert(key.to_string(), self.data.len());
self.data.extend_from_slice(key.as_bytes());
self.data.push(b':');
self.data.extend_from_slice(value.as_bytes());
self.data.push(b'\0');
}
pub fn get(&mut self, key: &str) -> Option<String> {
match self.cache.get(key) {
Some(&offset) => {
let start = offset + key.len() + 1;
let end = self.data[start..]
.iter()
.position(|&c| c == b'\0')
.unwrap_or(self.data.len() - offset);
Some(String::from_utf8(self.data[start..start + end].to_vec()).unwrap())
}
None => None,
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let mut db = Database::new();
db.set("123", "value1");
db.set("423", "value2");
assert_eq!(db.get("123"), Some(String::from("value1")));
assert_eq!(db.get("423"), Some(String::from("value2")));
}
}The Database struct holds the data file in a Vec<u8> and the hash index in aHashMap<String, usize>. The set method adds a new key-value pair to the hash index and appends the data to the end of the data file. The get method looks up the byte offset in the hash index and then reads the data from the data file.
How the Hash Index is Used
In this implementation, the hash index is used to map keys to byte offsets in the data file. When a new key-value pair is added to the database, the byte offset of the start of the value is added to the hash index. The key is stored in the data file as a byte string, followed by a colon (:) separator, followed by the value as another byte string, and ending with a null character (\0).
When a value is retrieved from the database, the byte offset of the value is retrieved from the hash index, and the value is read from the data file. The byte offset of the start of the value is calculated as the length of the key plus one for the colon separator. The end of the value is found by searching for the null character in the data file. If the null character is not found, then the length of the data file minus the byte offset is used as the end of the value.
Advantages and Disadvantages of Different Delimiters
Comma (”,”) Delimiter
Pros:
- Easy to read and understand.
- Commonly used in various file formats, such as CSV and JSON.
- Often supported natively by programming languages and databases.
Cons:
- Can be problematic when the data itself contains commas.
- May require additional parsing when the data is not well-formatted.
- Can be inefficient for large datasets, as searching for commas can be computationally expensive.
Line Break (“\n”) Delimiter
Pros:
- Easy to read and understand.
- Provides a clear separation between different records or lines of data.
- Often used in text-based file formats, such as log files and plain text documents.
Cons:
- Can be problematic when the data itself contains line breaks.
- May require additional parsing when the data is not well-formatted.
- Can be inefficient for large datasets, as searching for line breaks can be computationally expensive.
Null (“\0”) Delimiter
Pros:
- Can be used to represent arbitrary data, including binary data.
- Can be efficient for large datasets, as searching for null characters can be faster than searching for commas or line breaks.
- Provides a clear separation between different records or pieces of data.
Cons:
- Not as human-readable as comma- or line break-delimited data.
- May require additional parsing when the data is not well-formatted.
- May not be supported natively by all programming languages and databases.
Conclusion
Hash indexes are a powerful tool for efficiently looking up data based on a key. In log-structured storage engines, hash indexes are used to map keys to byte offsets in the data file. This makes lookups fast and efficient, and enables log-structured storage engines to handle large databases with millions or billions of records. While hash indexes can be inefficient for range queries, they are ideal for use in log-structured storage engines, where data is stored in an append-only log file.
References